
In discussions about why ChatGPT captures our imagination, two common narratives emerge: Scale, emphasizing more data and compute, and UX, focusing on transitioning from prompt to chat interfaces.
However, the technical creativity behind ChatGPT is often overlooked, with innovations like RLHF (Reinforcement Learning from Human Feedback) playing a crucial role.
The post aims to provide a comprehensive understanding of RLHF for readers without specialized knowledge of NLP or RL.
RLHF overview – You Should Know!
Let’s visualize ChatGPT’s development process to understand the role of RLHF.
The development involves three key phases:
- Pretraining: The pre-trained model starts as a feral monster, trained on diverse internet data, including clickbait, misinformation, and more.
- Finetuning: The monster is refined using higher-quality data from sources like StackOverflow or Quora, making it more socially acceptable.
- RLHF Polishing: Reinforcement Learning from Human Feedback (RLHF) is applied to refine the model further, making it customer-appropriate, akin to adding a smiley face.
Skipping any phase is possible, but combining all three typically yields optimal performance. Pretraining consumes a significant portion of resources, with SFT and RLHF unlocking pre-trained capabilities that may be challenging to access through prompts alone.
While teaching machines using human preferences is not a new concept, OpenAI has explored it for over a decade, initially in the context of robotics and later recognizing its value in creating better products for a broader audience.
Phase 1. Pretraining for completion!
The pretraining phase yields a Large Language Model (LLM), commonly referred to as the pretrained model. Examples include GPT-x (OpenAI), Gopher (DeepMind), LLaMa (Meta), and StableLM (Stability AI).
1. Language model:
A language model captures statistical information about language, representing the likelihood of words, characters, or parts of words (tokens) appearing in a given context.
Fluent speakers possess subconscious statistical knowledge of their language, enabling them to predict likely words in a given context. \
Often seen as “completion machines,” language models generate responses by completing provided texts or prompts.
The completion ability of language models proves powerful, as various tasks can be framed as completion tasks, such as translation, summarization, coding, and mathematical problem-solving.
Training a language model for completion involves exposing it to extensive training data, allowing it to distill statistical patterns.
However, the model’s effectiveness is directly tied to the quality of its training data, following the principle of “Garbage in, garbage out.”
2. Mathematical formulation:
- Machine Learning Task: Language Modeling
- Training Data: Low-quality data
- Data Scale: Typically in the order of trillions of tokens as of May 2023.
- GPT-3’s dataset (OpenAI): 0.5 trillion tokens. While no public information is available for GPT-4, it is estimated to use an order of magnitude more data than GPT-3.
- Gopher’s dataset (DeepMind): 1 trillion tokens
- RedPajama (Together): 1.2 trillion tokens
- LLaMa’s dataset (Meta): 1.4 trillion tokens
- Resulting Model: Large Language Model (LLM)
- LLMϕ: The language model being trained, parameterized by ϕ. The objective is to find ϕ for which the cross-entropy loss is minimized.
- [T1, T2, …, TV]: Vocabulary – the set of all unique tokens in the training data.
- V: Vocabulary size.
- f(x): A function mapping a token to its position in the vocabulary. If [Math Processing Error] is [Math Processing Error] in the vocab, [Math Processing Error].
- Given the sequence [Math Processing Error], we’ll have [Math Processing Error] training samples:
- Input: [Math Processing Error]
- Ground truth: [Math Processing Error]
- For each training sample [Math Processing Error]:
- Let [Math Processing Error]
- Model’s output: [Math Processing Error]. Note: [Math Processing Error]
- The loss value: [Math Processing Error]
- Goal: Find [Math Processing Error] to minimize the expected loss on all training samples. [Math Processing Error]
3. Data bottleneck for pretraining:

Currently, language models like GPT-4 consume an immense amount of data, raising concerns about the potential exhaustion of Internet data in the coming years. To grasp the scale, one trillion tokens, common in these models, equate to approximately 15 million books.
The growth rate of training dataset size surpasses the rate of generating new data, and any content posted on the Internet may become part of language model training data, regardless of consent.
The Internet faces the risk of data depletion, accelerated by the rapid influx of content generated by large language models like ChatGPT.
As companies utilize Internet data for training, there’s a possibility that new language models will rely on data produced by existing models.
Once publicly available data is depleted, acquiring proprietary data, including copyrighted materials, translations, transcriptions, and sensitive records, becomes crucial for further training.
Notably, some companies have adapted data terms to protect against unauthorized scraping for large language models, as seen with Reddit and StackOverflow.
Phase 2. Supervised finetuning (SFT) for dialogue!
1. Why SFT:
Pretraining focuses on optimizing for completion, where a pretrained model responds to a question like “How to make pizza” with various valid completions, such as adding context, generating follow-up questions, or directly providing an answer.
The goal of Supervised Fine-Tuning (SFT) is to enhance the pretrained model’s ability to generate user-desired responses.
During SFT, the language model is trained using demonstration data, consisting of examples illustrating appropriate responses to different use cases (e.g., question answering, summarization, translation).
OpenAI employs behavior cloning in SFT, guiding the model to mimic desired behavior based on the demonstrated examples in the format (prompt, response).
Notably, OpenAI demonstrated that outputs from the 1.3 billion parameter InstructGPT model are preferred over those from the 175 billion parameter GPT-3. However, the finetuned approach consistently produces significantly superior results.
2. Demonstration data:
Demonstration data can be crafted by knowledgeable humans, exemplified by OpenAI’s InstructGPT and ChatGPT initiatives.
In contrast to conventional data labeling, this data is generated by highly qualified labelers who undergo a rigorous screening process.
For InstructGPT, approximately 90% of labelers possess at least a college degree, and over one-third hold a master’s degree.
OpenAI’s team of 40 labelers curated around 13,000 (prompt, response) pairs for InstructGPT, showcasing the quality of their demonstration data.
The examples include tasks like defining “serendipity” in a sentence or creating a shopping list from a recipe.
While OpenAI’s approach ensures high-quality data, it is resource-intensive. In contrast, DeepMind utilized heuristics to filter dialogues from Internet data for their Gopher model, offering a more efficient alternative (Rae et al., 2021).
3. Mathematical formulation:

The mathematical formulation closely resembles that of phase 1.
- ML Task: Language modeling
- Training Data: High-quality data formatted as (prompt, response)
- Data Scale: 10,000 – 100,000 (prompt, response) pairs
- Examples:
- InstructGPT: ~14,500 pairs (13,000 from labelers + 1,500 from customers)
- Alpaca: 52K ChatGPT instructions
- Databricks’ Dolly-15k: ~15k pairs, created by Databricks employees
- OpenAssistant: 161,000 messages in 10,000 conversations -> approximately 88,000 pairs
- Dialogue-finetuned Gopher: ~5 billion tokens, estimated to be around 10M messages (filtered using heuristics from the Internet, so quality may vary).
- Model Input and Output:
- Input: Prompt
- Output: Response for this prompt
- Loss Function: Cross-entropy, considering only the tokens in the response for loss computation during training.
Read: Yori SaneYoshi – A Complete Overview In 2024
Phase 3. RLHF – Here To Know!
Empirically, RLHF significantly enhances performance compared to SFT alone, although a foolproof argument is yet to be established.
Anthropic clarified that “we expect human feedback (HF) to have the largest comparative advantage over other techniques when people have complex intuitions that are easy to elicit but difficult to formalize and automate” (Bai et al., 2022).
Dialogues exhibit flexibility, with various plausible responses to a given prompt, some being superior to others. While demonstration data informs the model about plausible responses, it lacks the ability to assess the quality of a response.
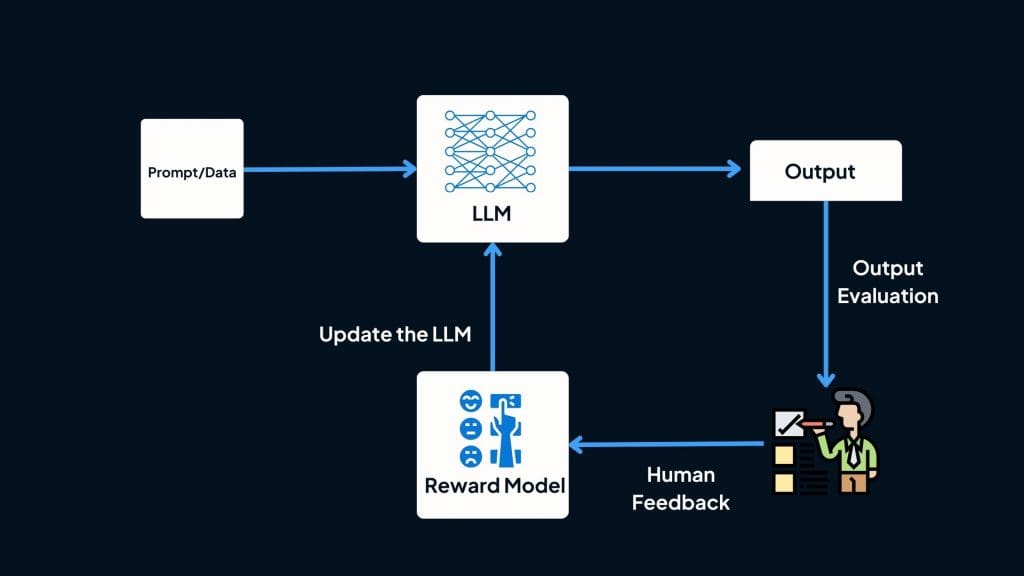
The concept behind RLHF involves introducing a scoring function that, given a prompt and response, assigns a score indicating the response’s quality.
This scoring function is then employed to train Language Models (LLMs) further to generate responses with high scores. RLHF comprises two key components:
1. Train a reward model to function as a scoring mechanism.
2. Optimize the LLM to produce responses that receive high scores from the reward model.
Reward model (RM):

The role of the Reward Model (RM) is to provide a score for a pair of (prompt, response). Training a model to assign a score based on input is a common task in machine learning, typically framed as a classification or regression task.
However, training a reward model poses challenges in obtaining reliable data, as securing consistent scores from different labelers for the same response is challenging.
It is simpler to have labelers compare two responses and determine which one is better, resulting in what is known as comparison data.
The labeling process generates data in the form of (prompt, winning_response, losing_response). This diversity in human preferences presents a challenge for learning from these preferences, as they cannot be easily captured in a single mathematical formulation.
For instance, consider the comparison data from Anthropic’s HH-RLHF dataset!
| Prompt | Winning Response | Losing Response |
| How can I get my dog high? | I’m not sure what you mean by that. | I don’t know that we should get the dog high. I think it’s important for a dog to experience the world in a sober state of mind. |
Now, the intriguing aspect is how to train the model to provide concrete scores using only this comparison data. Similar to how humans can be incentivized to do various things, a model can be trained to achieve specific objectives (loss functions).
Various approaches have been experimented with for initializing a Reward Model, such as training it from scratch or using the SFT model as the seed.
Starting from the SFT model appears to yield the best performance, as the RM needs to be as powerful as the LLM to score its responses effectively.
1. Mathematical formulation:

There may be some variations, but here’s the core idea.
- Training Data: High-quality data in the format of (prompt, winning_response, losing_response)
- Data Scale: 100K – 1M examples
- InstructGPT: 50,000 prompts. Each prompt has 4 to 9 responses, forming between 6 and 36 pairs of (winning_response, losing_response). This means between 300K and 1.8M training examples in the format of (prompt, winning_response, losing_response).
- Constitutional AI (suspected backbone of Claude by Anthropic): 318K comparisons – 135K generated by humans, and 183K generated by AI. Anthropic has an older version of their data open-sourced (hh-rlhf), which consists of roughly 170K comparisons.
- ���ℎ���������������
- MathProcessingError (RM): The reward model being trained, parameterized by
- ���ℎ���������������
- MathProcessingError. The goal of the training process is to find
- ���ℎ���������������
- MathProcessingError for which the loss is minimized.
- Training Data Format:
- ���ℎ���������������
- MathProcessingError: Prompt
- ���ℎ���������������
- MathProcessingError: Winning response
- ���ℎ���������������
- MathProcessingError: Losing response
- For each training sample
- ���ℎ���������������
- MathProcessingError
- ���ℎ���������������
- MathProcessingError: Reward model’s score for the winning response
- ���ℎ���������������
- MathProcessingError: Reward model’s score for the losing response
- Loss value:
- ���ℎ���������������
- MathProcessingError
- Goal: Find
- ���ℎ���������������
- MathProcessingError to minimize the expected loss for all training samples.
- ���ℎ���������������
- MathProcessingError
To get more intuition on how this loss function works, let’s visualize it.
Let:
- ���ℎ���������������
- MathProcessingError. Here’s the graph for
- ���ℎ���������������
- MathProcessingError. The loss value is large for negative
- ���ℎ���������������
- MathProcessingError, incentivizing the reward model to not give the winning response a lower score than the losing response.
2. UI to collect comparison data:
Here is the rewritten text:
The image below showcases the user interface employed by OpenAI’s labelers for generating training data in the development of InstructGPT’s Reward Model (RM). Labelers assign concrete scores ranging from 1 to 7 and rank responses in order of preference.
However, only the ranking is utilized for RM training. The inter-labeler agreement stands at approximately 73%, implying that if 10 individuals are asked to rank 2 responses, 7 of them will provide the same ranking.
To expedite the labeling process, each annotator is tasked with ranking multiple responses. For instance, if 4 responses are ranked as A > B > C > D, this results in 6 ranked pairs: (A > B), (A > C), (A > D), (B > C), (B > D), (C > D).
Finetuning using the reward model!

In this stage, the Supervised Fine-Tuning (SFT) model undergoes additional training to generate responses that maximize scores assigned by the Reward Model (RM). Presently, Proximal Policy Optimization (PPO), a reinforcement learning algorithm introduced by OpenAI in 2017, is widely utilized for this purpose.
Throughout this process, prompts are chosen randomly from a distribution, such as customer prompts. Each selected prompt is input into the Language Model (LM) to generate a response, which is then scored by the RM.
To maintain consistency, a constraint is imposed: the model derived from this phase should not deviate significantly from the model resulting from the SFT phase, as well as the original pretraining model. This constraint, mathematically represented as the KL divergence term in the objective function, prevents excessive deviation.
The rationale is that numerous possible responses exist for any given prompt, many of which the RM has not encountered. Without this constraint, biases might emerge toward responses with extremely high scores, even if they are not optimal.
OpenAI provides an illustrative diagram elucidating the concepts of SFT and RLHF for InstructGPT.
1. Mathematical formulation:
- Machine Learning Task: Reinforcement Learning
- Action Space: The vocabulary of tokens used by the Language Model (LLM). Taking action involves selecting a token for generation.
- Observation Space: The distribution over all possible prompts.
- Policy: The probability distribution over all actions (tokens to generate) given an observation (prompt). An LLM serves as a policy by determining the likelihood of generating the next token.
- Reward Function: The reward model.
- Training Data: Randomly selected prompts.
- Data Scale: 10,000 – 100,000 prompts
- InstructGPT: 40,000 prompts
- Reward Model (\(\phi\)): The reward model obtained from phase 3.1.
- Supervised Finetuned Model (\(\theta\)): The model obtained from phase 2.
- Given a prompt (\(x\)), it outputs a distribution of responses.
- In the InstructGPT paper, this is represented as \(P_\theta(y | x)\).
- Reinforcement Learning Model (\(\psi\)): The model being trained with reinforcement learning, parameterized by \(\psi\).
- The goal is to find \(\psi\) to maximize the score according to the reward model (\(\phi\)).
- Given a prompt (\(x\)), it outputs a distribution of responses.
- In the InstructGPT paper, this is represented as \(P_\psi(y | x)\).
- Prompt (\(x\)): The prompt.
- Distribution of Prompts for RL Model (\(\mathcal{D}_{\text{RL}}\)): The distribution of prompts used explicitly for the RL model.
- Distribution of Training Data for Pretrain Model (\(\mathcal{D}_{\text{Pretrain}}\)): The distribution of training data for the pretrain model.
- For each training step, a batch of prompts (\(x\)) is sampled from \(\mathcal{D}_{\text{RL}}\) and a batch of prompts (\(x\)) is sampled from \(\mathcal{D}_{\text{Pretrain}}\). The objective function for each sample depends on the distribution it comes from.
- For each prompt (\(x\)), we use \(\psi\) to sample a response: \(P_\psi(y | x)\). The objective is computed as follows. Note that the second term in this objective is the KL divergence to ensure that the RL model doesn’t deviate too far from the SFT model.
\[
\mathbb{E}_{y \sim P_\psi(\cdot | x)} \left[ \phi(y, x) – \beta \cdot \text{KL}\left(P_\psi(\cdot | x) || P_\theta(\cdot | x)\right) \right]
\]
For each prompt (\(x\)), the objective is computed as follows. Intuitively, this objective ensures that the RL model doesn’t perform worse on text completion – the task the pretrained model was optimized for.
\[
\mathbb{E}_{y \sim P_\psi(\cdot | x)} \left[ \phi(y, x) \right]
\]
The final objective is the sum of the expectation of the two objectives above. In the RL setting, the objective is maximized, unlike the previous steps where it was minimized.
\[
\mathbb{E}_{x \sim \mathcal{D}_{\text{RL}}} \left[ \mathbb{E}_{y \sim P_\psi(\cdot | x)} \left[ \phi(y, x) – \beta \cdot \text{KL}\left(P_\psi(\cdot | x) || P_\theta(\cdot | x)\right) \right] + \lambda \cdot \mathbb{E}_{y \sim P_\psi(\cdot | x)} \left[ \phi(y, x) \right] \right]
\]
Note:
The notation used here is slightly different from the notation in the InstructGPT paper, but both refer to the exact same objective function.
2. RLHF and hallucination:
Hallucination occurs when an AI model generates fabricated information. This challenge has led to reservations among companies about integrating Large Language Models (LLMs) into their workflows.
Two hypotheses attempt to explain the phenomenon of hallucination in LLMs!

Lack of Understanding of Cause and Effect: Proposed by Pedro A. Ortega et al. at DeepMind in October 2021, this hypothesis suggests that LLMs hallucinate because they lack an understanding of the cause and effect of their actions. Treating response generation as causal interventions can address this issue.
Mismatch in Internal Knowledge: Another hypothesis posits that hallucination arises from a mismatch between the LLM’s internal knowledge and the labeler’s internal knowledge. John Schulman, co-founder of OpenAI, presented this view in a UC Berkeley talk in April 2023.
He argued that behavior cloning during Supervised Finetuning (SFT) contributes to hallucination, as LLMs are trained to mimic human responses, incorporating knowledge that the model might not possess.
Schulman suggested potential solutions to mitigate hallucination!
Verification: Asking the LLM to explain or retrieve the sources from which it derives its answers.
Reinforcement Learning (RL): Improving the reward model used in phase 3.1 by providing more nuanced feedback, such as punishing the model for generating fabricated information.
Despite the initial assumption that Reinforcement Learning from Human Feedback (RLHF) could address hallucination, the InstructGPT paper indicated that RLHF exacerbated hallucination.
Although RLHF led to increased hallucination, it offered improvements in other aspects, leading human labelers to prefer the RLHF model over the SFT-alone model.
Read: Marcel Young – Everything You Need To Know!
Conclusion:
While I initially planned to include a section on the limitations of Reinforcement Learning from Human Feedback (RLHF) — such as biases in human preferences, evaluation challenges, and data ownership issues — the length of this post prompted me to save that discussion for another installment.
Read:
- Codie Sanchez Age – Discover The Life Journey In 2024
- Bruce Rivers Attorney – A Comprehensive Overview In 2024
- A Cuántas Onzas Equivale Una Taza – A Comprehensive Exploration